
2024년 5월, 감사원이 충격적인 결과를 발표했다. 정부가 2025년까지 2조 5천 억 원을 투입한 AI 학습용 데이터 구축 사업에서, 360종 가운데 122종이 품질 불량으로 활용되지 못했다. 사업비로 따지면 1148억 원이다. 게다가 어떤 사업은 무려 26개월 동안 데이터가 단 한 건도 만들어지지 않은 채 방치되어 있었다.
2년이 넘는 시간이다. 그동안 예산은 집행되고, 보고서는 올라가고, 일정은 흘러갔다. 데이터만 없었다. 어떻게 이런 일이 가능했을까.
대답은 의외로 단순하다. 멈춰 세울 사람이 없었기 때문이다.
자동차로 비유해보자. 운전 중에 길을 잘못 들었거나, 엔진이 멈춰버렸다고 치자. 정상이라면 브레이크를 밟고 차를 세운 다음 어디서부터 잘못됐는지 살펴봐야 한다. 그런데 지금 한국의 AI 데이터 사업에는 그 브레이크가 없다. 계기판에 속도는 찍히고 있으니 "운전 중"이라고 보고하지만, 실제로 가고 있는지 멈춰 있는지를 누구도 강제로 확인하지 않는다. 26개월 방치는 그래서 가능했다.
지난 기고에서 나는 "데이터의 질서를 세우는 것이 AI 3대 강국으로 가는 큰 돌"이라고 썼다. 이번 기고는 그 큰 돌을 어항에 넣을 때 손에 무엇이 쥐어져 있어야 하는지에 관한 이야기다. 그 답이 브레이크다.
지금 한국에서 쓰이는 AI 데이터 구축 방법론들은 모두 "필요하면 다시 돌아가서 고쳐도 된다"고 말한다. '돌아가도 된다'는 말은 '돌아가야 한다'는 말이 아니다. 강제 규정이 없으면 사람은 일정에 쫓겨, 예산에 쫓겨, 평가에 쫓겨 그냥 다음 단계로 넘어간다. 26개월 동안 데이터가 없어도 멈출 수 없는 이유가 여기에 있다.
핵심은 단순하다. 데이터 사업을 다섯 단계로 나누되, 마지막 단계에서 품질이 기준에 못 미치면 자동으로 첫 단계로 되돌아가게 만드는 것이다. 흥미롭게도 이 구조의 원형은 간호사들이 60년 넘게 환자를 돌볼 때 써온 절차에서 가져왔다. 환자 상태가 나아지지 않으면 처음부터 다시 살피는 그 방식이다. 의료 현장에서 검증된 순환 구조를 AI 데이터에 옮긴 셈이다.
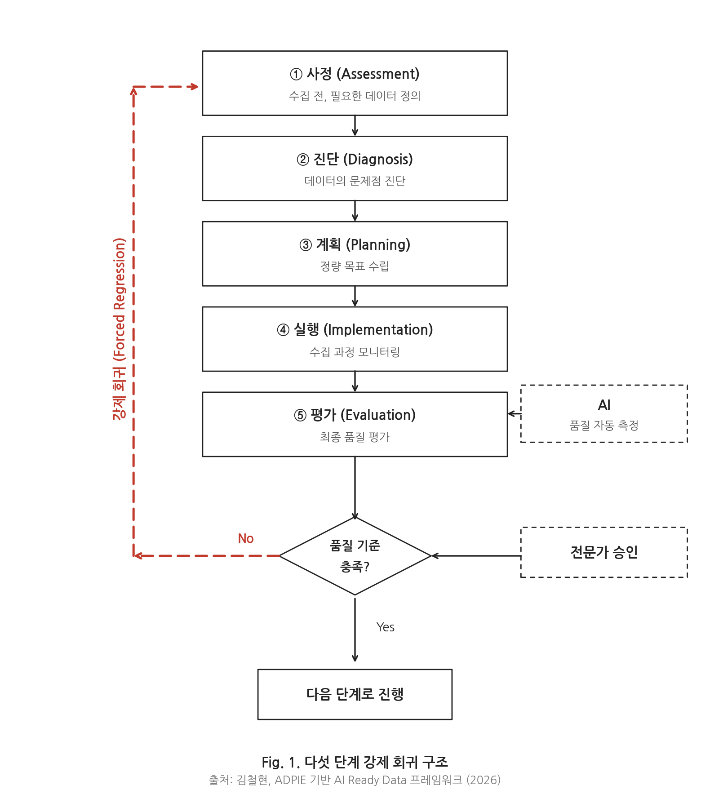 ADPIE 기반 AI Ready Data 수집 체계 프레임워크. 김철현
ADPIE 기반 AI Ready Data 수집 체계 프레임워크. 김철현다섯 단계는 이렇다. 첫째, 수집을 시작하기 전에 "어떤 AI를 만들 것이고, 그러려면 어떤 데이터가 어떤 품질로 필요한가"를 문서로 정의한다. 둘째, 데이터를 모으면서 무엇이 부족하고 어디가 잘못되었는지 진단한다. 셋째, 정량 목표가 담긴 수집 계획을 세운다. 넷째, 수집 과정을 실시간으로 모니터링한다. 다섯째, 최종 품질을 평가한다. 그리고 이 평가에서 기준에 미달하면, 선택이 아니라 규정에 의해 첫 단계로 돌아간다. 사람의 의지가 아니라 시스템이 멈추게 한다.
여기서 한 가지가 더 필요하다. 이 평가를 사람이 매번 손으로 하면 또 같은 함정에 빠진다. 그래서 필자가 설계한 솔루션에서는 AI가 품질 평가에 직접 참여한다. AI가 데이터의 빠진 부분, 모순되는 부분, 시간이 어긋난 부분을 자동으로 찾아내고, 문제가 있으면 어디로 돌아가서 무엇을 고쳐야 하는지 초안을 제시한다. 전문가는 그 초안을 검토하고 승인한다. 사람은 더 이상 검사자가 아니라 의사결정자가 된다. 브레이크를 AI가 자동으로 작동시키고, 사람은 그 브레이크를 풀지 말지를 결정하는 구조다.
그런데 그 AI가 외국 모델이라면 어떨까. 데이터 주권을 세우겠다면서 그 주권을 판단하는 두뇌를 미국이나 중국에 맡기는 것은 모순이다. 다행히 올해 8월, 정부가 추진해 온 한국형 AI 모델(독자 AI 파운데이션 모델)이 누구나 쓸 수 있도록 공개될 예정이다. 한국어와 한국 산업 환경에 최적화된 모델이다. 필자는 이 한국 AI가 강제 회귀 시스템의 두뇌 자리를 맡아야 한다고 본다. 한국어 데이터의 품질을 한국 AI가 판단하는 것, 그것이 진짜 데이터 주권이다.
이 방법론은 탁상공론이 아니다. 필자는 곧 시작될 국가 AI 데이터 구축 사업에서 이 구조를 실제로 적용할 준비를 하고 있다. 약 1년의 사업 기간을 3단계로 나누고, 각 단계마다 반드시 통과해야 하는 품질 게이트를 두었다. 첫 3개월은 수집을 시작하지 않는다. 대신 "무엇을 왜 어떤 품질로 모을 것인가"를 정의하는 데 쓴다. 농진청, 기상청, 환경부, 소방청 등 부처마다 흩어진 데이터를 하나로 묶으려면, 모으기 전에 기준과 형식이 먼저 합의되어야 하기 때문이다. 정의하고, 모으고, 검증하고, 실패하면 돌아간다. 이것이 26개월 방치를 구조적으로 불가능하게 만드는 방법이다.
2조 5천억을 투자해 1,148억이 사라진 이유는 알고리즘이 부족해서도, GPU가 부족해서도 아니다. 멈출 수 있는 장치가 없었기 때문이다. 브레이크 없는 차에 연료를 아무리 부어도 목적지에 도착하지 못한다. 먼저 할 일은 더 좋은 엔진을 만드는 것이 아니라 브레이크를 다는 것이다.
[참고자료]
· 감사원, 「인공지능(AI) 데이터 구축 사업 추진실태」 감사 결과 (2024.5.23.)
· 과기정통부·NIA, 「AI 데이터 품질관리 가이드라인 v3.5」 (2025.5.)
· 과기정통부, 독자 AI 파운데이션 모델 사업 (2026.3.25. 국무회의)
· 김철현, 「간호과정(ADPIE) 기반 AI Ready Data 수집 체계 프레임워크」
※ 외부 필진 기고는 CBS노컷뉴스의 편집방향과 다를 수 있습니다. 김철현 (주)카라멜라 CSO·농촌진흥청 AI 기술 컨설팅 전문위원
김철현 (주)카라멜라 CSO·농촌진흥청 AI 기술 컨설팅 전문위원